start
Sequence to Sequence Learning with Neural Networks
1.使用4层LSTM,每层1000个单元–>长句表现好
2.第一个在encode将输入句子用lstm编码成一个固定的维度的向量(cnn无序列化顺序)
3.将input sentence逆序输入可以明显改善LSTM模型,说是减小“minimal time lag”
Neural Machine Translation by Jointly Learning to Align and Translate
用encoder的所有hidden state的加权平均来表示context,权重表示decoder中各state与encoder各state的相关性,原始seq2seq认为decoder中每一个state都与input的全部信息(用last state表示)有关,而这篇文章则认为只与相关的state有关系,即在decoder部分中,模型只将注意力放在了相关的部分,对其他部分注意很少。

context vector是一个加权平均,权重用了一个最简单的mlp来计算,然后归一化。这里的权重反应了decoder中的state s(i-1)和encoder中的state h(j)之间的相关性。这篇文章在encoder部分采用了BiRNN。
在机器翻译中,attention model可以理解为source和target words的soft alignment,一个很经典的图,越亮的地方表示source和target中的words相关性越强(或者说对齐地越准),图中的每一个点的亮度就是前面计算出的权重
虽然在文章中并没有用到Attention这个词,但其实就是这篇文章提出的attention model
Empirical evaluation of gated recurrent neural networks on sequence modeling
这篇是虽然不是第一个提出gru的,但是系统的对比了lstm和gru。传统RNN 有两个主要的问题: 梯度消失, 长期记忆急速衰减。LSTM 不会每次都重写 memory,而是可以通过 input/forget gate 在需要的时候尽量地保留原来的 memory,LSTM/GRU 中额外增加的 cell state,让它们能记住较早之前的某些特定输入,同时让误差反向传播时不会衰减地太快
实验后, LSTM/GRU 在收敛速度和最后的结果上,都要比经典 RNN 要好,但 LSTM 和 GRU 在不同的数据集和任务上虽然互有优劣但差异不大,具体使用 LSTM 还是 GRU 视情况而定。但是gru参数少
Sequence-to-sequence rnns for text summarization
1、Encoder-Decoder with Attention:Encoder是一个双向GRU-RNN,Decoder是一个单向GRU-RNN,两个RNN的隐藏层大小相同,注意力模型应用在Encoder的hidden state上,一个softmax分类器应用在Decoder的生成器上。没有啥特别的
2、Large Vocabulary Trick:large vocabulary trick(LVT)技术到文本摘要问题上。每个mini batch中decoder的词汇表受制于encoder的词汇表,decoder词汇表中的词由一定数量的高频词构成。重点解决的是由于decoder词汇表过大而造成softmax层的计算瓶颈。
比较合适摘要,因为摘要中的很多词都是来自于原文之中。所以将decoder的词汇表做了约束,降低了decoder词汇表规模,加速了训练。
3、Vocabulary expansion:为了生成新颖的有意义的词,扩展LVT词表,将原文中所有单词的一度最邻近单词扩充到词汇表中,最邻近的单词在词向量空间中cosine相似度来计算
4、Feature-rich Encoder:设计了一些的features,比如:词性,命名实体标签,单词的TF和IDF。将features融入到了word embedding上,对于原文中的每个单词构建一个融合多features的word embedding,而decoder部分,仍采用原来的word embedding。
5、Switching Generator/Pointer:由于word embedding对低频词的处理并不友好,所以用decoder/pointer机制来解决这个问题。模型中decoder带有一个开关,如果开关状态是打开generator,则生成一个单词;如果是关闭,decoder则生成一个原文单词位置的指针,然后拷贝到摘要中,挺像copy
6、Hierarchical Encoder with Hieratchical Attention:关键词和关键句子都很重要,所以用两个双向RNN来捕捉这一个是word-level,一个是sentence-level,在两个层次上都使用注意力模型
A neural attention model for abstractive sentence summarization
很经典的ABS,之后都作为Baseline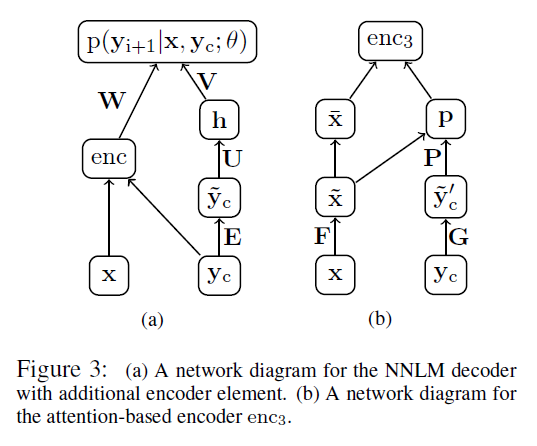
论文尝试了三种 encoder 的方式,分别是 Bag-of-Words,CNN 和 Attention-Based,结果 enc1 < enc2 < enc3。另外,还尝试了与 extractive 结合,就有了 ABS+。即在每次解码出一个词的时候,不仅考虑神经网络对当前词的预测概率 logp,还要开个窗口,去找一找当前窗口内的词是否在原文中出现过,如果有的话,概率会变大。相当于加了个feature吧,当然ABS+ 的效果好于 ABS
目标函数是negative log likelihood,使用mini-batch SGD优化
DUC-2004: Rouge-1:26.55/Rouge-2:7.06/Rouge-L:22.05
Gigaword: Rouge-1:30.88/Rouge-2:12.65/Rouge-L:28.34
Neural headline generation on abstract meaning representation
baseline是朴素的使用了 encoder-decoder去做生成式(ABS)。 由于Abstract meaning representation(AMR图) 具有高度的结构化句法和语义信息,如何融入nn,得到这样一个attention-based AMR encoder-decoder model ,结果也就提升了一个点
Pointer networks
是attention (decode生成y时,需要计算X1到Xn对生成y的贡献) 的一个变体
之前的翻译模型无法解决某类问题:在decode时,若source sentence长度是变化的(增多),则target classes也是变化的(增多)。也可以描述为seq2seq输出严重依赖输入
而Ptr-Nets在输入序列中就挑出一个member作为输出,避免了这个问题。不像attetion将source通过encoder变成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素
经典的attention:
Ptr-Net中的attention:
Pointer Net没有上面传统attention的最后一个公式(将权重关系a和隐式状态整合为context vector),而是直接进行通过softmax,指向输入序列选择中最有可能是输出的元素。
然后使用得到的softmax结果去拷贝encoder对应的输入元素作为的decoder输入的向量。
(本身是解决旅行商、凸包等,nips2015),显而易见,如果是抽取式摘要直接sentence labeling就行,如果是生成式,就是下面的pointer generator这篇,这种混合的模型能够从原文中直接复制词语,因而可以提高摘要的准确率并处理OOV词语,同时还保留下了生成新词语的能力
总而言之,Ptr-Net解决了seq2seq模型中output dictionary大小固定的问题,并且是一种用attention把copy机制带入生成模型中的方法
copynet
copy机制是对于seq2seq(attention)的decoder时候的,具体来说有两点改变:1.decoder的状态更新会加一个位置信息进去,因为copy的时候需要知道那个词在source里面的位置(hidden state),当然如果不在source里面,位置信息=0
2.另一个是,输出是个generate-code和copy-mode(从input sentence 中选词)的混合模型,即最终词的概率p是两种算p的方法的和,分别对应两种处理表示source sentence的向量来算p的方法:attentive read 和 selective read。
attentive read 和 selective read都是根据词在不同的集合(vocab或者source sentence的交、补集)有不同的打分函数,其中有参数需要学习。比如target不在source里面p(c)就是0,若target仅在source里面p(g)就是0
Get To The Point: Summarization with Pointer-Generator Networks
解决三个问题::产生不准确的事实类细节、生成重复的词,以及不能很好的处理OOV
既可以通过pointing直接从原文中copy单词又保留了通过generator生成新词的能力;另外,用coverage来记录已经总结出的内容,防止重复
即是模型=pointergenerator+coverage=seq2seq+attention+copy+coverage
- Sequence-to-sequence attentional model
biLSTM作为encoder,decoder hidden state被用来计算注意力分布(source中的词的概率分布),用来计算hidden state的加权和作为新的t时间的context vector,和decoder state 过两个线性变化之后softmax来计算target 词的概率分布
- pointer-generator=Sequence-to-sequence attentional model+copy

重要的是,每一步还计算了一个概率值P_gen,这代表从词表中生成单词的概率。这个P_gen用来给seq2seq 模型softmax后的结果和Ptr-Net产生的来自source词的概率分布进行加权求和
两点说明,一个是,这里copy-mode是直接从attention权重计算的词的分布中去采样。另一个是,感觉p_gen是一种soft的形式,另外它计算方法是(h_t*是source向量+s_t是这一步的decoder state+xt是这一步的decoder的输入就是grandtruth)再sigmoid
- coverage
这个是为了解决重复输出的问题,在decoder的每一步,更新一个coverage vector,是之前所有time step的decoder时attention权重的直接累加,可以来记录model已经关注过source中哪些词(也就是目前的生成已经覆盖到哪些词),并让这个向量影响attention权重的计算
同时在算loss的时候,摘要任务里要加一个coverage loss惩罚关注同一位置(相同的coverage)才行
疑问:为什么在Get To The Point看结果里面extractive方法还比pointer-generator-copy的rouge得分更高?
answer:新闻类重要的信息就是集中在前几句
Neural summarization by extracting sentences and words
把任务定义为分为sentence和word两个level的summarization。sentence level是一个序列标签问题,每个句子有0或1两个标签,为1表示需要提取该句作为总结。而word level则是一个限定词典规模下的生成问题,词典规模限定为原文档中所有出现的词。
首先在encoder端将document分为word和sentence来encode,word使用CNN encode得到句子表示,接着将句子表示输入RNN得到encoder端隐藏层状态。从word到sentence的encode体现了本文的hierarchical document encoder的概念。
在decoder端根据任务的不同使用不同网络结构,sentence任务就是一个简单的有监督下二分类问题,使用RNN网络结构更新decoder端隐藏层状态, decoder端隐藏层状态串联encoder端隐藏层状态后接入一个MLP层再接sigmoid激活函数得到句子是否被extract的概率。
word任务则是用传统的attention-based的方法来计算每个词的概率。但要注意本文的计算的attention不是word-level attention,而是encoder端sentence-level attention。
应该是之前都是seq2seq在abstractive summarization上,本文想解决seq2seq用在extractive summarization。(之前是对每个句子计算一个分数,然后分类这种)
SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents
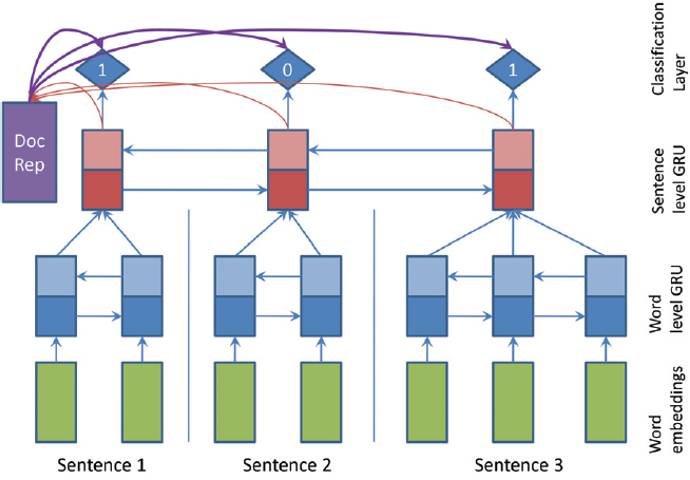
这是一个两层RNN。
最下面是词的输入,第一层是词级别的双向GRU,用来建模句子表示。第二层的每个句子的隐层各自做average pooling作为各自句子的表示。包括2类RNN结果,一个forward,一个backward,是双向的RNN
第二层是句子级别的双向GRU,使用word level layer的输出结果hidden state representation串联(用[]表示)起来作为本层的input。得到隐层再做average pooling就能够得到文档的表示。
最后利用文档的表示来帮助我们依次对句子做分类。 (abstractive summary引入到extractive model中作为训练数据)
预测的时候,遍历每个句子,使用二分类的方法判断这个句子需不需要加入摘要里面去,对应于一个logistic layer,最后分类层的公式如下:
content意思是与hidden输出有关,salience就是看文档和摘要关系,novely是看摘要和句子s_j的关系。其中s_j是到达第j个句子的已经生成的部分摘要的表示,d是文章的表示。 Wh表示第j个句子的信息, hWd计算的是当前的句子和文章表示的相似度,-hW*tanh(s)表示的是当前的句子能够带来多少“新”的信息,接下来的三项分别表示绝对位置,相对位置和偏置。所以文中说他自己可解释性很强。
最后Loss采用的负对数似然。在最终选取摘要的时候不是简单的分类,而是根据每个句子的概率高低排序,选择概率最高的前几句即可。
注意两个事情:一个是,abstractive仅用于训练,即在extractive的基础上,利用摘要的信息,来优化extractive的模型,后面test的时候也是extractive的方式
另一个是,对于SummaRuNNer的loss function中真实数据的label的产生是用去每次从所有句子中选出一个句子,让该句子加入摘要中,就直到能够使ROUGE值增加得最多,一直选择,直到ROUGE值不变或者减少的时候停止。
Selective Encoding for Abstractive Sentence Summarization

一种选择性编码模型。模型包含了一个句子encoder、选择门网络和带注意力decoder。
Encoder是一个BiGRU,Selective编码选择层是将词的h_i与句子的s拼接到一起,放到一个前馈网络里来生成输出h’_i。文中说是s=[h←_1, h→_n]就代表整个句子。h←_1表示从右到左读取了整个句子, h→_n表示从左到右读取了整个句子。总体来说,编码选择层来对编码信息进行过滤,通过控制从编码器到解码器的信息流来构建额外的一层信息表示,该层表示为摘要构建了一种特殊的语义表示。
Decoder的不同在于maxout。GRU使用s_t-1, c_t-1, y_t-1更新s_t;s_t+h_i计算e_i然后归一化得到权重α_i,乘以h’_i得到context向量c_t,和s_t、y_t-1一起放到一个maxout层(k=2)中得到output,然后使用softmax。这个maxout层比较特殊,相当于不同层网络之间有2套互相独立的权重参数,输出z的时候选一个能让z大的参数。这里encoder使用了BiGRU,decoder得到的输出是2d,使用k=2的maxout合并相邻的两个数值,将输出降为d维(其实并不知道为什么这么做)。
不过效果还可以
Gigaword(Rush et al., 2015): Rouge-1:36.15/Rouge-2:17.54/Rouge-L:33.63
Gigaword(ours): Rouge-1:46.86/Rouge-2:24.58/Rouge-L:43.53(sounds something strange??? why so high?)
DUC2004: Rouge-1:29.21/Rouge-2:9.56/Rouge-L:25.51
Ranking Sentences for Extractive Summarization with Reinforcement Learning
在之前的cnn+seq2seq(ConvS2S),引入结合主题模型的注意力机制
如何引入:结合多步注意力机制和带偏置生成机制的方法,将主题信息整合进了自动摘要模型中
强化学习:在 ConvS2S 的训练优化中使用了 self-critical,以ROUGE 来直接做reward,说是有助于缓解曝光偏差问题(exposure bias issue):由于只将一个模型暴露于训练数据的分布而不是其自身的分布中。在训练过程中,模型由groundtruth来预测下一个单词,而在推理过程中,它们会生成下一个单词,并将预测的单词作为输入。因此,在测试过程中,每个步骤的错误会累积并导致性能的恶化
self-critical:根据输入序列x生成两个输出序列,第一个序列是通过贪婪地选择最大化输出概率分布的词来获得的,而另一个输出序列是通过从分布中取样生成的。在获得了两种序列的ROUGE之后,计算差值,然后最小化了损失:-差值*logp,由此可以直接优化离散的评估指标

什么是topic信息:topic model是一种传统的用于发现抽象主题思想或隐藏语义的统计模型。其实这样做相当于主题模型来获取文档的隐含知识,相当于增大先验知识。
A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization
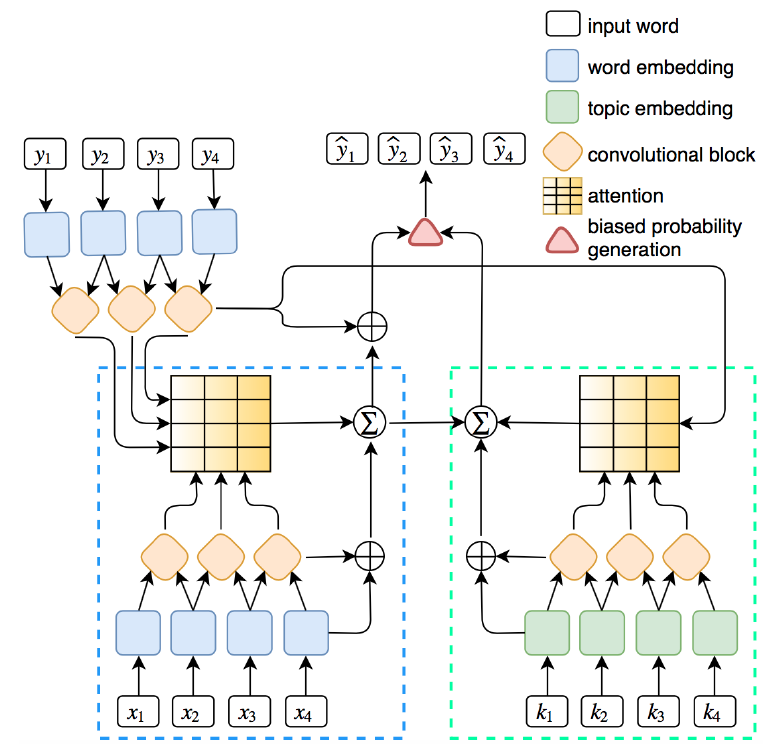
总而言之就是Conv Seq2seq + LDA + Reinforcement Learning。这个图上源序列的单词和主题的嵌入是由相关的卷积块(左下方和右下方)编码的。然后,通过计算解码器表示(左上角)和文字/主题编码器表示的点积来共同关注单词和主题。最后,通过一个有偏差的概率生成机制来生成目标序列。
跟上一篇非常类似,将topic信息引入到ConvS2S模型中并使用 self-critical 强化学习训练方法(SCST)来进行优化。引入词语和主题信息,加入多步注意力机制
1、Position Embedding: 每个词的输入=词向量+位置向量。就是embedding的时候加一个位置信息e=(w1+p1,…,wm+pm)
2、Gated Linear Unit: encoder decoder都是通过叠加几个卷积层来构建的。每层的卷积操作做个线性变化到2d维,输出重写成[A; B],然后两边残差连接喂入下一层。使用门控线性单元(GLU)
3、Multi-Step Attention: 先对隐层状态做个embedding再计算权重,此处跟上一篇一样
4、Topic Embedding: 对于每个主题,抽取出前N个词出来构成词表K,预训练得到topic embedding。对于输入中的每个词,如果在K中,则使用topic embedding,否则使用word embedding。
吉布斯抽样技术的经典LDA方法,对主题嵌入初始化的语料库进行预训练,并为有偏差的概率生成过程提供候选方案。嵌入值被规范化为一个平均值为0和0.1的分布。这篇论文选取了最高的N=200个单词,在每个主题中获得了主题词集的最高概率。
5、Joint Attention: 在Topic-aware Conv过程中,计算Attention权重时,除了要计算当前decoder隐层状态与每个encoder输出的点积,还要计算当前decoder隐层状态与input ebmedding中每个encoder输出的点积,再求和并归一化作为权重。
6、Biased Probability Generation:其中有个线性变化,有点复杂
7、Reinforcement Learning: 策略和上一篇一模一样,λ_RL=0.99
Gigawords: Rouge-1:36.92/Rouge-2:18.29/Rouge-L:34.58
DUC2004: Rouge-1:31.15/Rouge-2:10.85/Rouge-L:27.68
LCSTS(word): Rouge-1:39.93/Rouge-2:33.08/Rouge-L:42.68
A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss
本文提出在分层编码解码模型的基础上利用分层attention机制将抽取式与生成式结合。并提出了不一致性损失函数将两者结合提高生成质量。
- 提出一个抽取式和提取式融合的模型来做 summarization,利用抽取式模型对句子的重要程度打分,获得 sentence-level 的 attention 进而影响生成式对每个词的 word-level 的 attention权重;提出 inconsistency loss;
因为单纯的抽取式rouge高但是很不流利,生成式模型可读性更高且较为简洁,但是在某些事实细节方面往往不够准确。
CNN/Daily Mail 数据集 ROUGE 分数超过抽取式模型 lead-3,本文的模型可看作是 pointer-generator 和抽取式模型的融合;
用Hierarchical 的结构(word-level encoding 和 sentence-level encoding),分别对 sentence 和word 做 attention;sentence 的 attention 权重使用 sigmoid;word 的 attention 权重计算时用 sentence-level 的 attention 权重进行 scale;
Inconsistency Loss 对 decode 每个 step 的 topK attention word 的 word-level 和 sentence-level 的 attention 乘积做 negative log;鼓励 word-level attention sharp,sentence-level 的 attention high。
抽取式和生成式方法可以作为两个独立步骤训练,也可以采取端到端的方式进行训练,分开训练时,抽取式部分直接将信息量较大的句子输出,生成式部分只接受部分原始句子作为输入;端到端训练时,抽取式方法对句子进行打分,生成式部分会在句子打分的基础上,更新对每个词的attention权值。在端到端训练时,生成式部分权值较大的词可能不在抽取式权值较大的句子里面,因此文章提出了不一致损失来约束该情况。
只超越了lead3…
5.loss有4个部分,抽取、生成、coverage、inc(最重要)
Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting
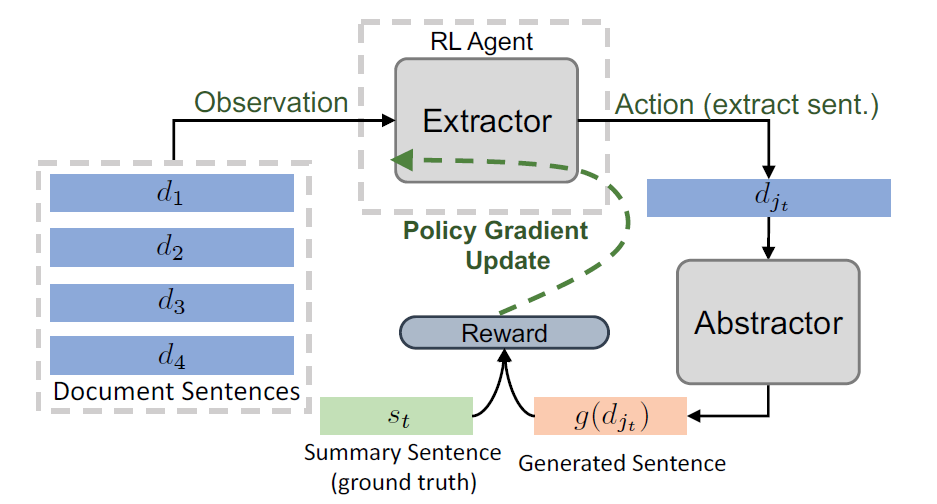
1、用cnn做句子level编码
2、把cnn的输出作为一个bilstm的输入,去学习一个Hierarchical的更强的句子表示
3、Sentence Selection:用一个pointer作为抽取式,去抽重要句子(曾被选过,则为-无穷大)
4、Abstractor Network:改写器是 encoder-aligner-decoder + copynet(就是get the point)
快: parallel decoding
5、强化学习仅调整Extractor参数,不调整Abstractor参数,避免生成的句子可读性差,同样使用Policy Gradient学习算法。直接用rouge作为reward。两次离散化
6.几个trick:伪标签算rouge最大,extract部分用eoe表示让抽取停止,beam search抽句子(防止ngram重复太大)
性能
CNN/Daily Mail: Rouge-1:40.88/Rouge-2:17.80/Rouge-L:38.54
Neural Document Summarization by Jointly Learning to Score and Select Sentences
又是将句子排序和选择联合在一个端到端模型里,这篇文章joint就在于把当前权重最大的句子的隐层状态作为decode下一个time step的输入,这样相当于同时拿文章信息和之前已经抽取句子的信息再次对其他句子进行attention操作,这样让抽取句子的信息起到一个抑制作用