first try to write in english && want to make friends in our studio say hello to Natural Language Processing
Introduction
Natural language processing (NLP) is all about creating systems that process or “understand” language in order to perform certain tasks. So what are these tasks?
For example:
qa
sentiment analysis
- image to text mappings
- machine translation
- name entity recognition
traditional approach
The traditional approach to NLP involved a lot of domain knowledge of linguistics itself. Such as phonemes and morphemes.
just try to understand the following word—“uninterested”
“un” indicates an opposing or opposite idea and “ed” can specify the time period (past tense)
But we are not skilled linguists
dl approach
representation learning can be describe as a general term.
Word Vectors
we have to represent each word as a d-dimensional vector. Let’s use d = 6.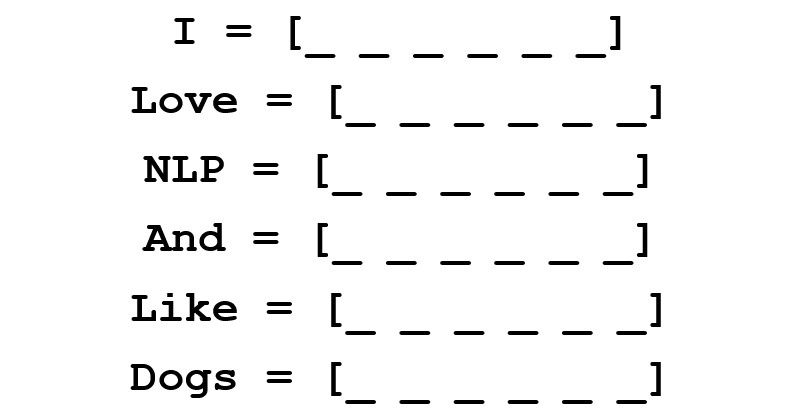
we want this six dimensional vector to represents the word and its context, meaning, or semantics.
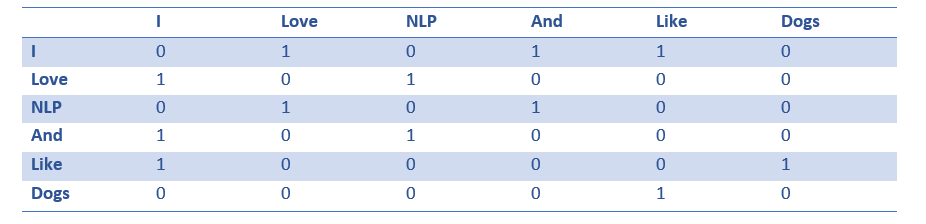
A coocurence matrix is a matrix that contains the number of counts of each word appearing next to all the other words in the data.
So now using the matrix we have word vectors,but the question is that the matrix which would be extremely sparse (lots of 0’s) when the training data are very large. Definitely it has poor storage efficiency.
so let us come to Word2Vec.
Word2Vec
The basic idea is that we want to store as much information as we can in this word vector while still keeping the dimensionality at a manageable scale (25 – 1000 dimensions).
We want to predict the surrounding words of every word by maximizing the log probability of any context word given the current center word
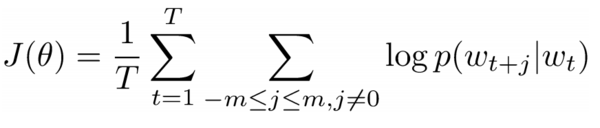
Word2Vec finds vector representations of different words by maximizing the log probability of context words given a center word and modifying the vectors through SGD(https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf、http://nlp.stanford.edu/pubs/glove.pdf)
RNN
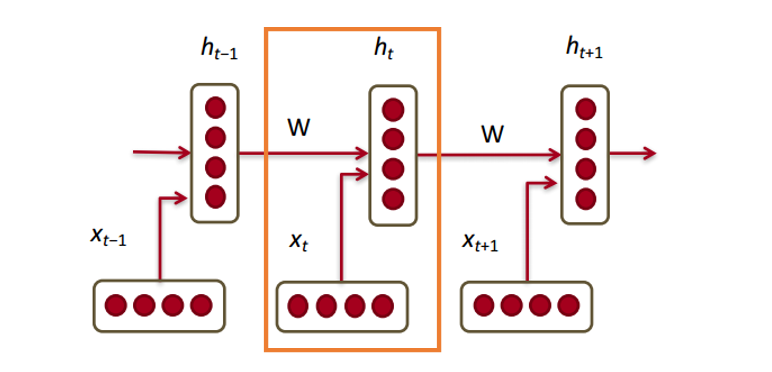
Each of the vectors has a hidden state vector at that same time step (ht, ht-1, ht+1). Let’s call this
one module=each of the vectors(x)+hidden state vector
hidden state:about the hidden state vector at previous time step and the word vector.W is weight matrix.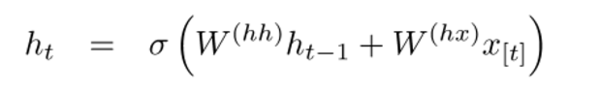
When we want a output.The last time is t.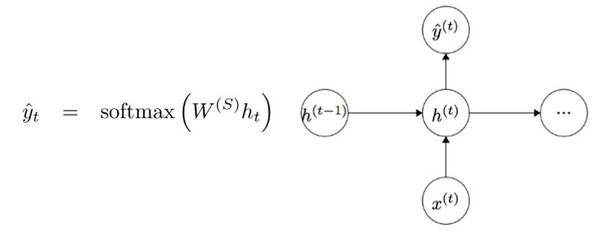
gated recurrent units
Why we need to capture long distance dependencies? During backpropagation, such as if the initial gradient is a small number (< 0.25), then by the 3rd or 4th module, the gradient will have vanished.
The GRU provides a different way of computing this hidden state vector h(t). Included:an update gate, a reset gate, and a new memory container.
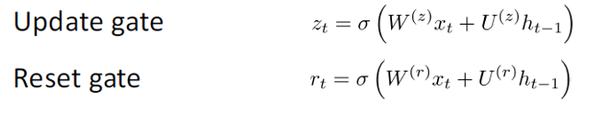
two gateas have different weights
a new memory container: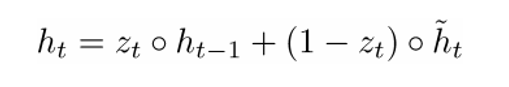
LSTM

as an extension to the idea behind a GRU
different in the number of gates that they have (GRU – 2, LSTM – 3)
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Memory Networks
详见另一篇博客
神经机器翻译