自动聊天system的解决方案和技术挑战

图灵测试:人机对话无法判断对方,即持续聊天,任何query给出合适replies,考虑到用户个体差异
相关的概念:问答系统(给一个明确的答案factoid,或者why、how等等)、对话系统(通过对话完成一个事情,没有闲聊,科研圈子小)、自动客服FAQ
技术基因
why和how形的问答、community qa、corpus mining、faq mining
共同点:有大量的qa数据,配以准确的匹配&排序算法,那么问答系统是可能的
重要结论:
文本的相似性和相关性(更重要)是两个不同需求
短文本相关性很难计算(常识上的同义词)

词语贡献\机器翻译(问题和恢复是一种另类的翻译对)|LDA主题建模\meta-data
两条主要路线
一条好走大家都能走,一条看起来很难走但是沿途风景美
1、基于ir的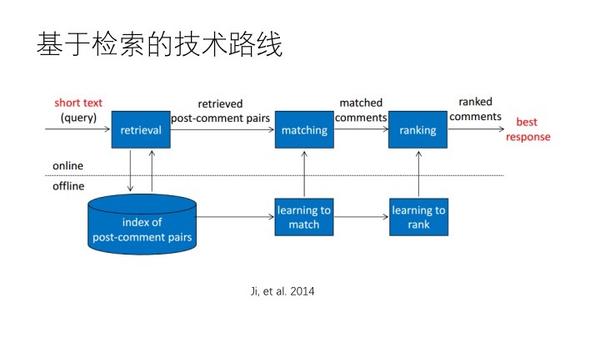
建立一个索引,query问答库的匹配,用文本相似度找,把候选答案再做一个相关性计算,排序得到最相关的,框架上就相当于检索系统
细化的三层的逻辑架构
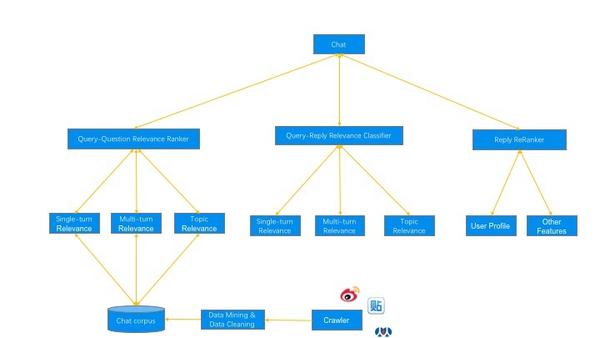
首先计算query和question关系,找到和query最相似的问题后再通过问题找到答案;再做一个排序,考虑多轮语意相关性和主题相关性;第三层考虑非文本相关的需求,比如考虑用户差异,再排序
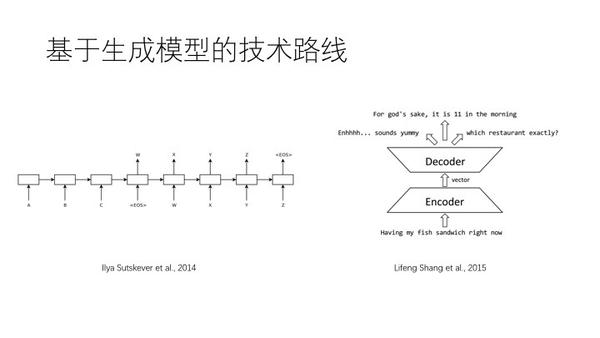
基于生成模板
中文句子可以直接输出英文,而且机器翻译和聊天有潜在关联,则同样sequence to sequence,用深度学习做encoder到decoder
用基于ir的方法可以使句子可读性比较好,query保证回复的多样性,debug很容易。挑战是要rank,事情比较复杂。
基于生成model式的,构建模型很容易,直接训练,不需要维护问答库,可读性很差,回复总会是说“我也觉得是这样”

难度:上下文、外部知识、个性元素、评价

深度学习从浅入深列举,对抗学习23333
短文本的语意相关性计算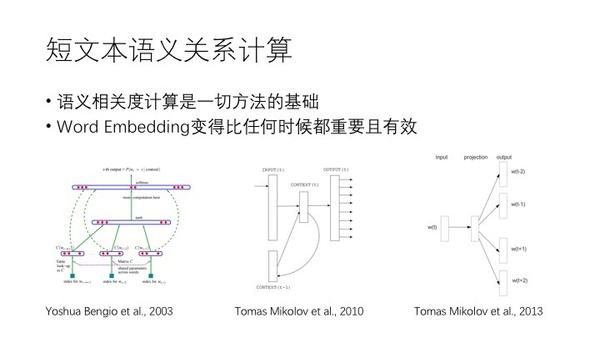
词向量很重要,算夹角表示距离
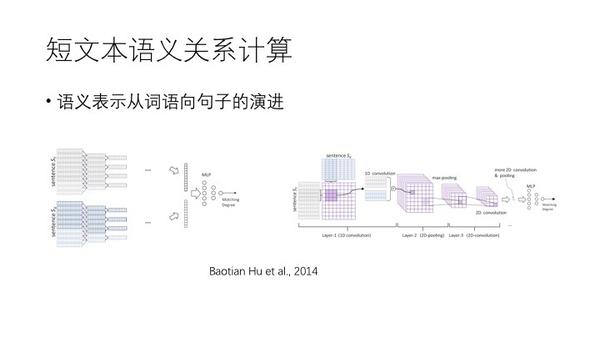
但是按维数相加,会产生损失,所以应该是产生句子向量,上面就是两种2014年的paper,一种是做卷积,后一种是词语之间的关系在二维上排开,细化计算语义关系产生矩阵再做卷积。即是词语向量输入,句子向量输出。
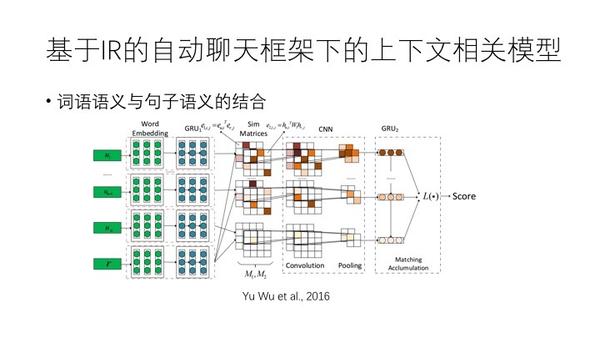
如上图,上下文引入,要有对话历史。通过序列化的gru模型,两个层面的计算,一个是两个词语之间形成embedding,另一方面gru形成句子级别的向量矩阵,形成句子之间的矩阵。两个平行的矩阵,分别做卷积。2016年
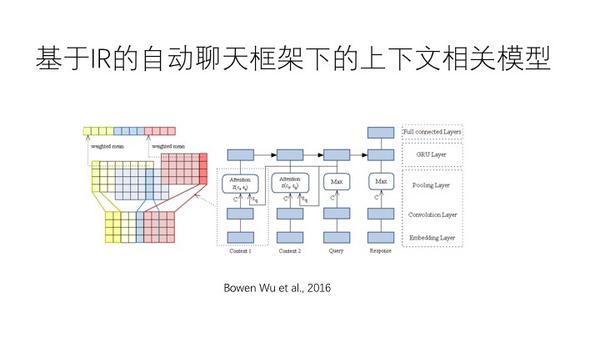
如上图,看句子是否相关。在cnn上面做attention机制,query在语义背景下,使用了两种方法,一种是得到模糊的语义背景,一种是????然后用这两种关系排除result
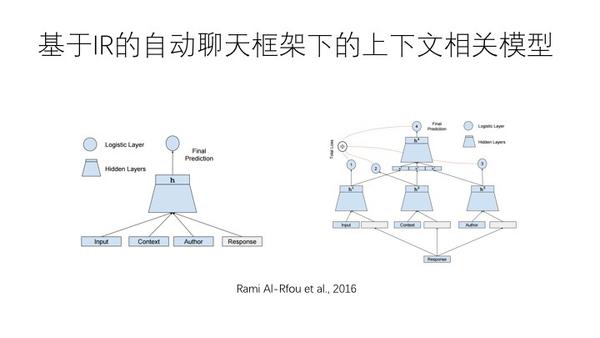
如上图,GOOgle的方法,把作者的东西引进来,算,然后分解。上下文情况下人工排序
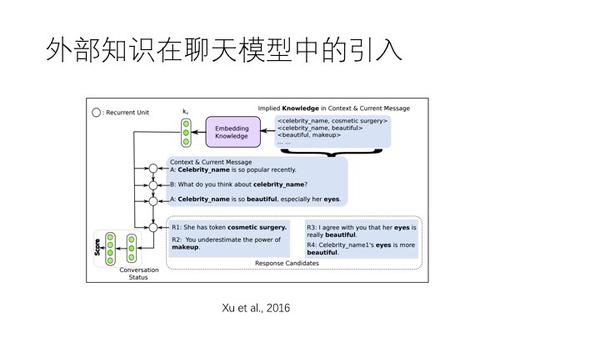
如上图,外部知识如何引入
生成式
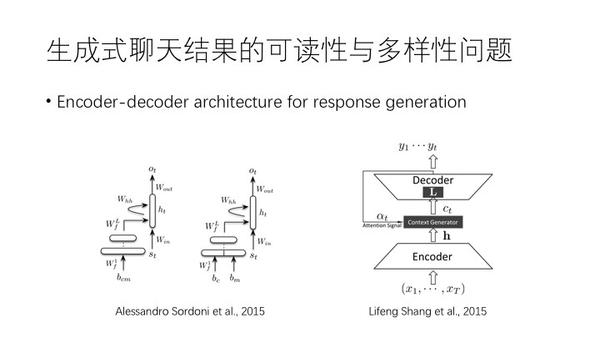
attention的方法引入
上图,强化学习的引入,关键是怎么给model以奖惩。三个维度,一生成的model能引出更多样性的回复,推动聊天进展,强相关于topic
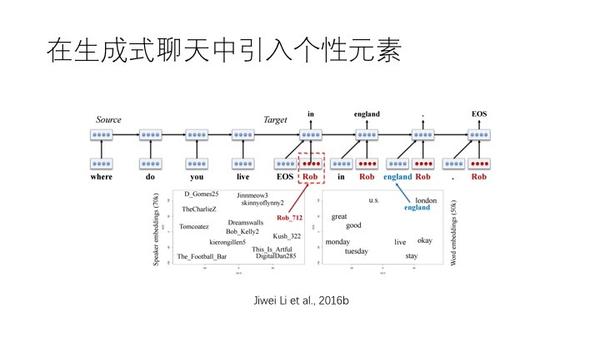
上图,id和词语向量放在一起,每个词生成都考虑人是谁
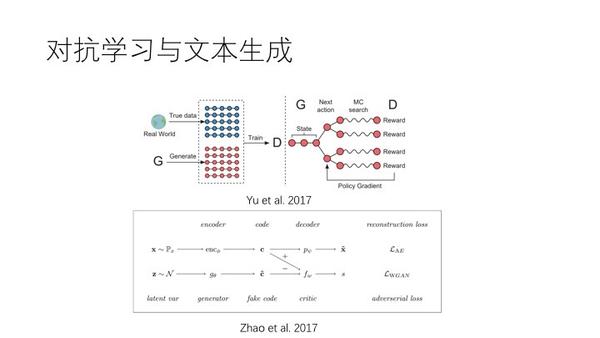
上图,对抗学习,引入文本生成。假如一句话不能判断是谁说的,就说明生成器很好。图形的生成是可导的,但是词语的选择这一步就是不可导的,那么关联就没有了?用强化学习绕过不可导。或者说语意向量是可导的,这样来关联两个生成器。
评价
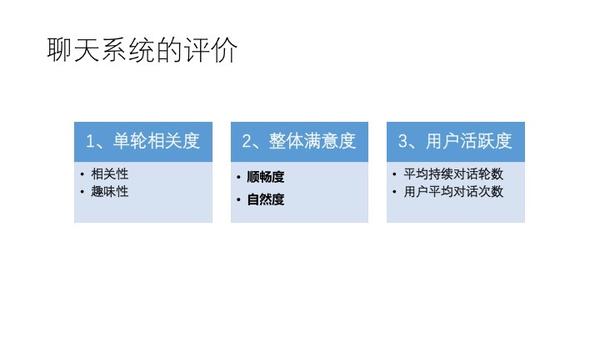
对话轮数是有区别的,可以赋权重
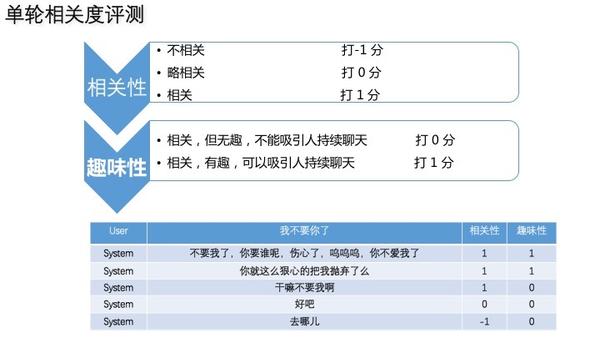
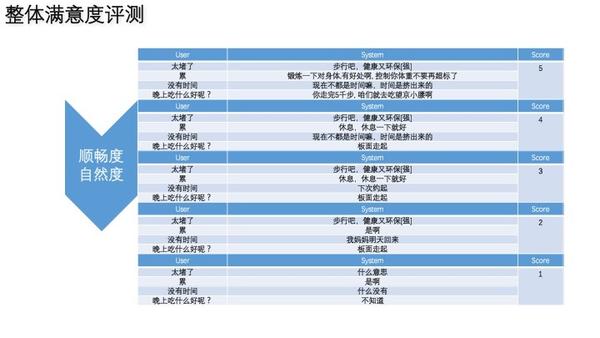
挑战
训练集不统一(reddit更好)

情感交流,这是提高用户体验到关键


全nlp:问答、机器翻译、自动文摘、语音的自动合成与识别、ir、文本分类

信息检索:相关性、扩展以后的相关性、个性化检索
特征取得要强