bop资格赛弃坑之路
由于这次资格赛涉及了过多的高级操作,就算会写bot也过不了资格赛,就比较无语,但是还是学到了些东西的
题目
资格赛任务题是基于文档的问答任务(Document-based Question Answering task, DBQA),它是对于给定的一篇文档(Document)和一个从文档中提出的自然语言问题(Question),参赛队伍需要使用提供的数据集训练模型算法,让模型可以回答问题,回答时仅限于从组成该文档的句子中选出能回答该问题的句子(Answer Selection in Question Answering)。鼓励参赛队伍发挥算法创造力并使用各种资源来训练模型,比如句子匹配模型(Sentence Matching Model),以使模型能准确地回答问题。
基于文档的问答系统DBQA
给出了训练数据开发数据测试数据,训练数据给出了三元组,问题是同样的问题,七句话来自同一个篇章。第一列是答案标签,第六行是1:是答案,其他不是答案:是0。任务是:给你一个篇章再给一个问题,选出篇章中的一句来保证这是当前问题的答案。根据答案标签来训练问题答案句匹配模型,但是实际测试时只会给当前的篇章和问题,没有答案标签,要排序,排出最相关的一句话
提示:1、数数,重复的字词很多,就有问题答案关系
2、词向量。每个句子都可以转化成词向量,表示当前词的语言。然后看词向量上的距离
3、深度学习工具,做模型上的训练,使问题和正确答案相关性非常强,以实现答案抽取
胡老师
用深度学习做文本领域的自动问答,分析输入问题基于文本的内容来给出答案
最土的做法:端对端的基于神经网络的自动问答模型,需要基于LSTM模型及其变体,比如有需要有web记忆模块的功能;再比如说用gru编码给定的文本信息作为知识,在编码给定信息的时候要用词向量表示文本,然后用gru表示给定的问题
然后用attention机制来表示问题和需要记忆的答案和情景之间的交互来生成答案,所以是一个需要用动态神经网络机制来实现的端对端的联合训练的神经网络系统。
要做的话建议用双向的LSTM模型来同时建立问题和文档的联合表示,然后通过一个分类器来预测答案。
TensorFlow
谷歌就开源了其用来制作AlphaGo的深度学习系统Tensorflow
|
|






!!! 看看
attention机制
真正火起来应该算由于是google mind团队的这篇论文《Recurrent Models of Visual Attention,他们在RNN模型上使用了attention机制来进行图像分类。
随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点
《Recurrent Models of Visual Attention》
他们研究的动机是受到人类注意力机制的启发。人们在进行观察图像的时候,其实并不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分.

该模型是在传统的RNN上加入了attention机制(即红圈圈出来的部分),通过attention去学习一幅图像要处理的部分,每次当前状态,都会根据前一个状态学习得到的要关注的位置l和当前输入的图像,去处理注意力部分像素,而不是图像的全部像素。这样的好处就是更少的像素需要处理,减少了任务的复杂度。可以看到图像中应用attention和人类的注意力机制是很类似的,接下来我们看看在NLP中使用的attention。
Attention-based RNN in NLP
他们把attention机制用到了神经网络机器翻译(NMT)上,NMT其实就是一个典型的sequence to sequence模型,也就是一个encoder to decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后在使用一个RNN进行解码翻译到目标语言,传统的模型如下图: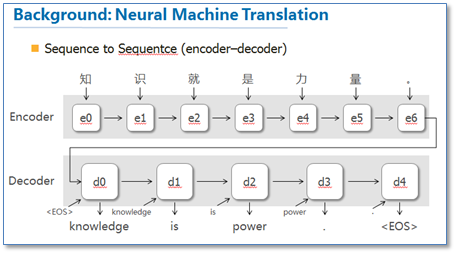
这篇论文提出了基于attention机制的NMT,模型大致如下图: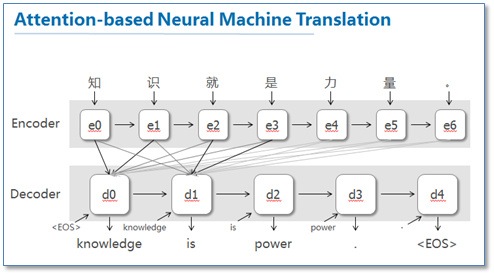
图中我并没有把解码器中的所有连线画玩,只画了前两个词,后面的词其实都一样。可以看到基于attention的NMT在传统的基础上,它把源语言端的每个词学到的表达(传统的只有最后一个词后学到的表达)和当前要预测翻译的词联系了起来,这样的联系就是通过他们设计的attention进行的,在模型训练好后,根据attention矩阵,我们就可以得到源语言和目标语言的对齐矩阵了。具体论文的attention设计部分如下: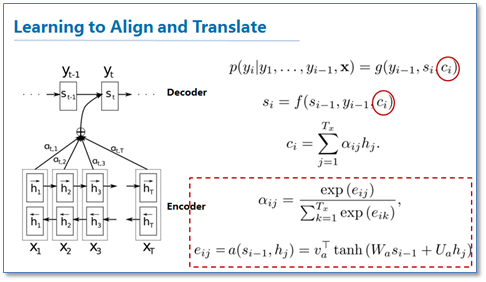
可以看到他们是使用一个感知机公式来将目标语言和源语言的每个词联系了起来,然后通过soft函数将其归一化得到一个概率分布,就是attention矩阵。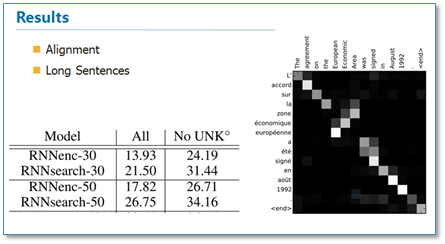
从结果来看相比传统的NMT(RNNsearch是attention NMT,RNNenc是传统NMT)效果提升了不少,最大的特点还在于它可以可视化对齐,并且在长句的处理上更有优势。
Effective Approaches to Attention-based Neural Machine Translation
他们的工作告诉了大家attention在RNN中可以如何进行扩展,这篇论文对后续各种基于attention的模型在NLP应用起到了很大的促进作用。在论文中他们提出了两种attention机制,一种是全局(global)机制,一种是局部(local)机制。
作者的实验结果是局部的比全局的attention效果好。
这篇论文最大的贡献我觉得是首先告诉了我们可以如何扩展attention的计算方式,还有就是局部的attention方法。
Attention-based CNN in NLP
随后基于Attention的RNN模型开始在NLP中广泛应用,不仅仅是序列到序列模型,各种分类问题都可以使用这样的模型。那么在深度学习中与RNN同样流行的卷积神经网络CNN是否也可以使用attention机制呢?《ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs》这篇论文就提出了3中在CNN中使用attention的方法,是attention在CNN中较早的探索性工作。
传统的CNN在构建句对模型时如上图,通过每个单通道处理一个句子,然后学习句子表达,最后一起输入到分类器中。这样的模型在输入分类器前句对间是没有相互联系的,作者们就想通过设计attention机制将不同cnn通道的句对联系起来。
第一种方法ABCNN0-1是在卷积前进行attention,通过attention矩阵计算出相应句对的attention feature map,然后连同原来的feature map一起输入到卷积层。具体的计算方法如下。
第二种方法ABCNN-2是在池化时进行attention,通过attention对卷积后的表达重新加权,然后再进行池化,原理如下图。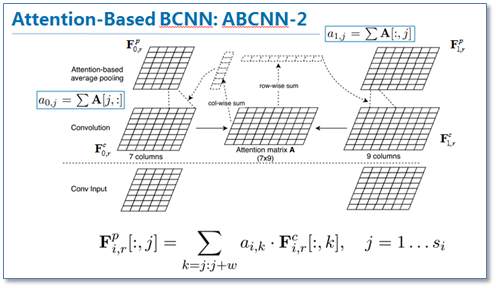
第三种就是把前两种方法一起用到CNN中,如下图
这篇论文提供了我们在CNN中使用attention的思路。现在也有不少使用基于attention的CNN工作,并取得了不错的效果。
总结
Attention在NLP中其实我觉得可以看成是一种自动加权,它可以把两个你想要联系起来的不同模块,通过加权的形式进行联系。目前主流的计算公式有以下几种:
通过设计一个函数将目标模块mt和源模块ms联系起来,然后通过一个soft函数将其归一化得到概率分布。
目前Attention在NLP中已经有广泛的应用。它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。
不过在NLP中的attention机制和人类的attention机制还是有所区别,它基本还是需要计算所有要处理的对象,并额外用一个矩阵去存储其权重,其实增加了开销。而不是像人类一样可以忽略不想关注的部分,只去处理关注的部分。
!!!!
numpy
Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用。其实,list已经提供了类似于矩阵的表示形式,不过numpy为我们提供了更多的函数。
在 numpy 包中我们用数组来表示向量,矩阵和高阶数据结构。他们就由数组构成,一维就用一个数组表示,二维就是数组中包含数组表示。
矩阵的余弦看相似度
SVD
singular value decomposition是线性代数中一种重要的矩阵分解,在信号处理、统计学等领域有重要应用。 奇异值分解在某些方面与对称矩阵或厄米矩陣基于特征向量的对角化类似。
svd
gru模型
GRU模型与LSTM模型设计上十分的相似,LSTM包含三个门函数(input gate、forget gate和output gate),而GRU模型是LSTM模型的简化版,仅仅包含两个门函数(reset gate和update gate)。reset gate决定先前的信息如何结合当前的输入,update gate决定保留多少先前的信息。如果将reset全部设置为1,并且update gate设置为0,则模型退化为RNN模型。

从上面GRU模型和LSTM模型的定义可总结出区别如下
1:GRU包含2个门函数、LSTM包含三个门函数。
2:GRU模型没有output gate,因此它不需要计算输出。
3:LSTM中input gate和forget gate的作用分别为控制输入的信息和控制先前的信息。而GRU中由update gate同时控制输入和先前的信息,即公式中变量z。reset gate直接应用于先前的隐藏状态的控制,即公式中变量f。这样LSTM中reset的作用由GRU中reset和update gate共同完成。
4:输出不再需要加入一个非线性函数。
LSTM模型和GRU模型在应用中的选择
1:从上面的区别可以看出,GRU模型的参数相对更少,因此训练的速度会稍快,从实验中也可以得出该结论。
2:当你的训练数据足够多的时候,LSTM模型会表现的更好。
实验步骤
1:本次实验采用insuranceQA数据,你可以在这里获得。实验之前首先对问题和答案按字切词,然后采用word2vec对问题和答案进行预训练(这里采用按字切词的方式避免的切词的麻烦,并且同样能获得较高的准确率)。
2:由于本次实验采用固定长度的GRU,因此需要对问题和答案进行截断(过长)或补充(过短)。
3:实验建模Input。本次实验采用问答对的形式进行建模(q,a+,a-),q代表问题,a+代表正向答案,a-代表负向答案。insuranceQA里的训练数据已经包含了问题和正向答案,因此需要对负向答案进行选择,实验时我们采用随机的方式对负向答案进行选择,组合成(q,a+,a-)的形式。
4:将问题和答案进行Embedding(batch_size, sequence_len, embedding_size)表示。
5:对问题和答案采用相同的GRU模型计算特征(sequence_len, batch_size, rnn_size)。
6:对时序的GRU特征进行选择,这里采用max-pooling。
7:采用问题和答案最终计算的特征,计算目标函数(cosine_similary)。
参数设置
1:、这里优化函数采用论文中使用的SGD(采用adam优化函数时效果会差大概2个点)。
2、学习速率为0.1。
3:、训练100轮,大概需要6个小时的时间。
4、margin这里采用0.15,其它参数也试过0.05、0.1效果一般。
5、这里训练没有采用dropout和l2约束,之前试过dropout和l2对实验效果没有提升,这里就没有采用了。
6、batch_size这里采用问题30字、答案100字。
7、rnn_size为150(继续调大没有明显的效果提升,而且导致训练速度减慢)
8、目标函数采用cosine_similary。
实验效果对比
QA_CNN:0.62左右
QA_LSTM:0.66左右
QA_BILSTM:0.68左右
QA_GRU :0.6378左右
QA_BIGRU :0.669左右
注:这里分别实验了单向的GRU算法、双向的GUR算法、单向的LSTM和双向的LSTM算法。单向GRU/LSTM的算法只能捕获当前词之前词的特征,而双向的GRU/LSTM算法则能够同时捕获前后词的特征,实验证明双向的GRU/LSTM比单向的GRU/LSTM算法效果更佳。LSTM算法性能稍优于GRU算法,但是GRU算法训练速度要比LSTM算法快。实际使用可以根据自己的要求做出权衡。
!!!!!!!! gru模型算法和qa
LSTM模型
nlpir汉语分词系统
网址
可以线上演示
word2vec
word2vec是Google于2013年开源推出的一个用于获取词向量的工具包
从官方的介绍可以看出word2vec是一个将词表示为一个向量的工具,通过该向量表示,可以用来进行更深入的自然语言处理,比如机器翻译等。
N-gram模型
通过上面的语言模型计算的例子,大家可以发现,如果一个句子比较长,那么它的计算量会很大;
牛逼的科学家们想出了一个N-gram模型来简化计算,在计算某一项的概率时Context不是考虑前面所有的词,而是前N-1个词;
当然牛逼的科学家们还在此模型上继续优化,比如N-pos模型从语法的角度出发,先对词进行词性标注分类,在此基础上来计算模型的概率;后面还有一些针对性的语言模型改进,这里就不一一介绍。
通过上面简短的语言模型介绍,我们可以看出核心的计算在于P(wi|Contenti),对于其的计算主要有两种思路:一种是基于统计的思路,另外一种是通过函数拟合的思路;前者比较容易理解但是实际运用的时候有一些问题(比如如果组合在语料里没出现导致对应的条件概率变为0等),而函数拟合的思路就是通过语料的输入训练出一个函数P(wi|Contexti) = f(wi,Contexti;θ),这样对于测试数据就直接套用函数计算概率即可,这也是机器学习中惯用的思路之一。
|
|
词向量表示
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
最直观的就是把每个词表示为一个很长的向量。这个向量的维度是词表的大小,其中绝大多数元素为0,只有一个维度的值为1,这个维度就代表了当前的词。这种表示方式被称为One-hot Representation。这种方式的优点在于简洁,但是却无法描述词与词之间的关系。
另外一种表示方法是通过一个低维的向量(通常为50维、100维或200维),其基于“具有相似上下文的词,应该具有相似的语义”的假说,这种表示方式被称为Distributed Representation。它是一个稠密、低维的实数向量,它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特征。其特点是将词语的不同句法和语义特征分布到它的每一个维度上去表示。这种方式的好处是可以通过空间距离或者余弦夹角来描述词与词之间的相似性。
神经网络概率语言模型
神经网络概率语言模型(NNLM)把词向量作为输入(初始的词向量是随机值),训练语言模型的同时也在训练词向量,最终可以同时得到语言模型和词向量。
Bengio等牛逼的科学家们用了一个三层的神经网络来构建语言模型,同样也是N-gram 模型。 网络的第一层是输入层,是是上下文的N-1个向量组成的(n-1)m维向量;第二层是隐藏层,使用tanh作为激活函数;第三层是输出层,每个节点表示一个词的未归一化概率,最后使用softmax激活函数将输出值归一化。
得到这个模型,然后就可以利用梯度下降法把模型优化出来,最终得到语言模型和词向量表示。
word2vec的核心模型
word2vec在NNLM和其他语言模型的基础进行了优化,有CBOW模型和Skip-Gram模型,还有Hierarchical Softmax和Negative Sampling两个降低复杂度的近似方法,两两组合出四种实现。
无论是哪种模型,其基本网络结构都是在下图的基础上,省略掉了隐藏层;
分词处理
由于word2vec处理的数据是单词分隔的语句,对于中文来说,需要先进行分词处理。这里采用的是中国自然语言处理开源组织开源的ansj_seg分词器`
分词处理之后的文件内容如下所示:
下载实践
这里我没有从官网下载而是从github上的svn2github/word2vec项目下载源码,下载之后执行make命令编译,这个过程很快就可以结束。
|
|
处理结束之后,使用distance命令可以测试处理结果,以下是分别测试【足球】和【改革】的效果:

word2vec的模型是基于神经网络来训练词向量的工具;
word2vec通过一系列的模型和框架对原有的NNLM进行优化,简化了计算但准确度还是保持得很好;
word2vec的主要的应用还是自然语言的处理,通过训练出来的词向量,可以进行聚类等处理,或者作为其他深入学习的输入。另外,word2vec还适用于一些时序数据的挖掘,比如用户商品的浏览分析、用户APP的下载等,通过这些数据的分析,可以得到商品或者APP的向量表示,从而用于个性化搜索和推荐。
[word2vec词向量训练及中文文本相似度计算] (http://blog.csdn.net/eastmount/article/details/50637476)
所以突然发现是可以做到的,然而没时间了,我要下周就期末考试了,只能很惨的弃坑,不过这个坑要是小学期有时间一定填上